
The Data Engineering Trilemma: Balancing Cost, Speed, and Governance in Real-Time Pipelines
Business is not conducted in a vacuum. You press a button, clear an account, or an IoT sensor is triggered—but now your system has to make a decision. This level of impatience across the board has turned real-time analytics from a luxury into a necessity. Raw speed is no silver bullet. Pipelines will fail at the edges if you build fast data streams without considering cloud costs or security. This is not just about how fast the data moves, but about designing pipelines that are fast, cost-effective, affordable, and capable of operating without creating a constant operational headache.
When Real Time Truly Matters
Stop attempting to frame all business problems within a real-time paradigm. Most insights remain valuable even when they are delivered a few hours or days later. Reserve real-time pipelines for cases where latency is a value killer, such as fraud detection, automated system failures, or in-app user recommendations. In such cases, there is no luxury of even a second’s delay; the entire product depends on freshness.
In other situations where it is not necessary, do not impose the operational premium. More familiar incremental processes or micro-batching can typically deliver what the business needs without the complexity of stateful, continuous streams. It is best to begin pipeline development with a clear discussion about how fast the data truly needs to travel.
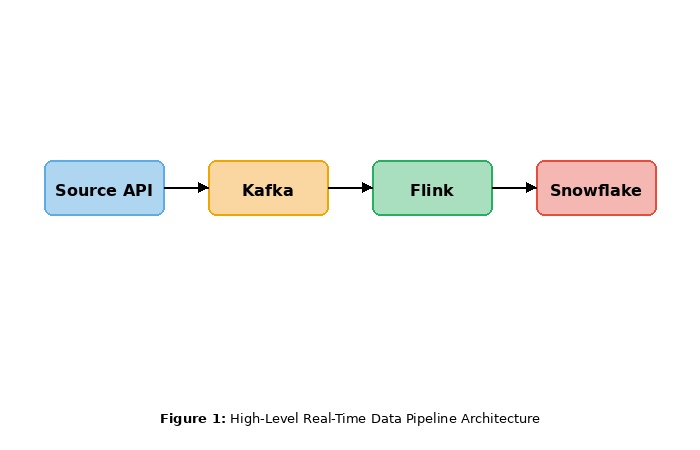
The Flow of Data From Source to Insight
Think of a data pipeline as an ecosystem. It receives API data, database data, or external streams and stores them for processing. That is the flow you must design in a real-time environment to ensure you can handle unexpected increases in traffic without collapsing.
It starts with consumption: you must decouple your sources and your downstream systems (typically with message brokers) so that an explosion of events does not immediately crash your architecture. This is followed by processing, which involves transforming raw events into
valuable metrics in real time using engines that filter, aggregate, and validate events. Finally, storage is the optimal way to retain data in a manner that is durable and easily accessible whenever it needs to be retrieved quickly. The reason for establishing these layers is that they prevent your pipeline from breaking down when exposed to heavy traffic surges.
Performance Is More Than Speed
Raw latency and system performance are concepts that are often used interchangeably within teams. There is no value in having sub-millisecond response times if the back end falls apart as traffic load intensifies. The same applies to speed, stability, and throughput. An unsuccessful pipeline may have a response time of ten milliseconds but still fail under Black Friday traffic.
Design to scale. Your processing engines must be able to scale out and scale in on demand. You should optimize your data formats to eliminate unnecessary reads and abort irrelevant computations early in the stream. Performance, in this context, is a continuous process, not a glittering benchmark achieved in a controlled experiment.
Keeping Costs Under Control Without Slowing Down
Uncontrolled real-time systems will literally set your cloud budget on fire. The usual culprits are infinite compute, exponential storage costs, and insensitive workloads. Cost efficiency must be designed in from the beginning; it cannot be treated as an appendix when the finance
department is already in a frenzy.
Smart pipelines are resource-efficient. They shift non-critical workloads to less expensive compute instances and reserve high-performance resources for the critical path. Embrace data lifecycle policies: hot data belongs in fast, expensive storage, but aging data should be proactively moved to colder, lower-cost storage as its value declines. Above all, demand must be carefully monitored. Bottlenecks are difficult to fine-tune, and costs that are not measured are impossible to reduce.
Governance as a Foundation, Not a Barrier
Data governance is often seen as an annoying impediment to the innovation engineers value. In reality, good governance enables you to scale without fear. Your data practices must be as strong as your infrastructure.
Control access to streams through role-based access controls (RBAC) to restrict them to specific individuals and services. Encrypt data both at rest and in transit. Manual compliance does not scale in a streaming environment, so automate your data retention and localization policies.
Teams with governance embedded in their culture will spend less time putting out compliance fires and more time relying confidently on their data.
Closing Thoughts
The irony of a perfectly optimized data pipeline is that no one notices its existence. It simply works. It can handle traffic spikes and scale down without anyone being disturbed at 3 AM, and it supports data governance without choking the data science team.
Such consistency is unremarkable and does not come easily. When you treat performance, cost, and security as a single pillar of your architecture—rather than competing forces—you begin to build systems that last. The real challenge of real-time systems is balance: move too fast, and you fail blindly. Cloud budget is not a minor concern that can be ignored in the pursuit of lower latency. Be strict with management, but flexible with innovation. Once you achieve that balance, real-time analytics becomes not a risky engineering experiment, but the core of your business.
NOTE: No TechCircle Journalist was involved in the creation/production of this content

Voolla Sandeep Kumar
Next Article